The value of great first-line support in a B2B startup
Learn more about how Kantega SSO values customer driven development to ensure product quality and market success.
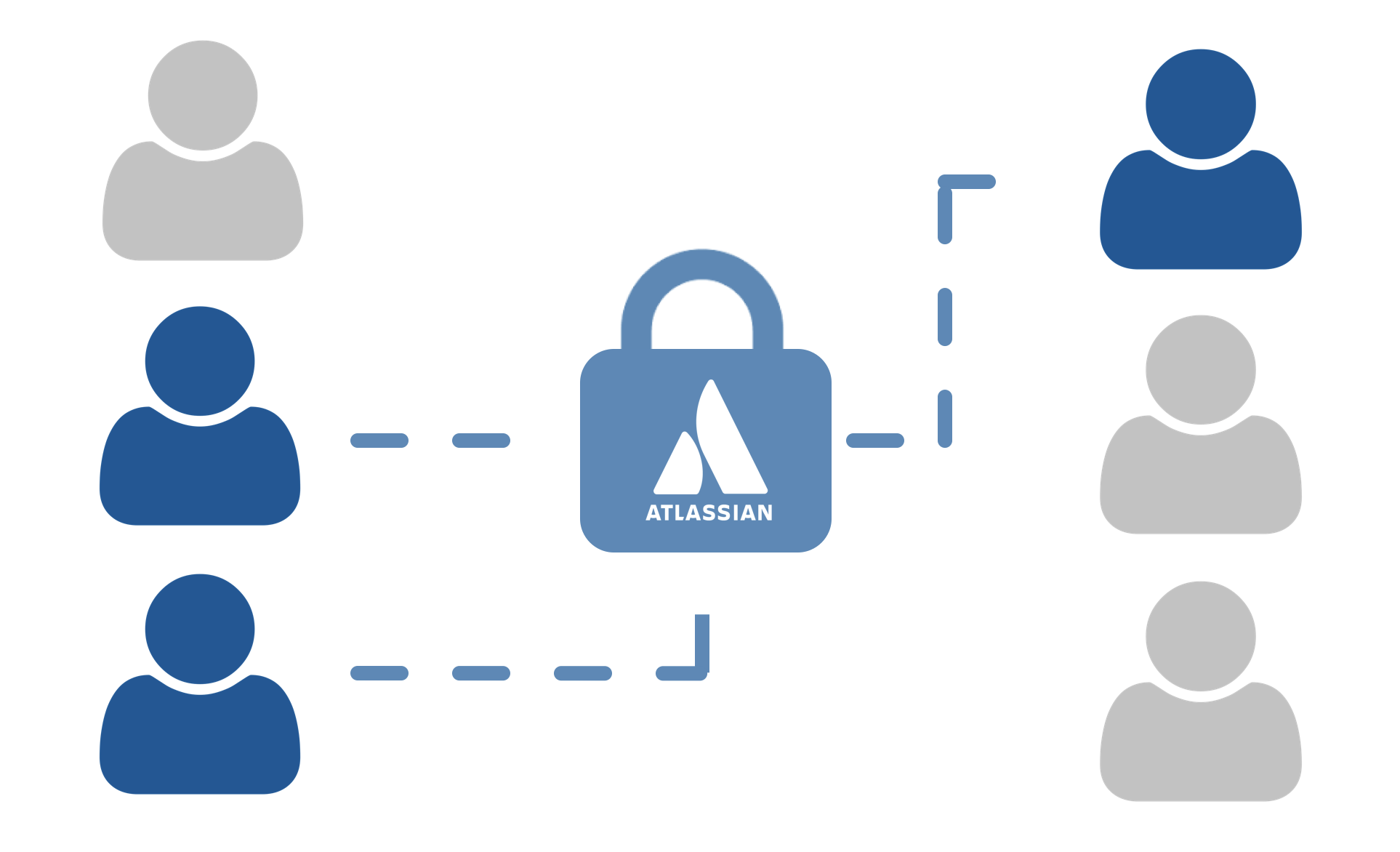
Pros and cons of Just-in-time provisioning and Synchronized cloud directories.
JIT provisioning allow users to be created, updated and activated in user directories when on-the-fly and when they log in through SAML SSO to the Atlassian applications. User data is provided from the identity providers through name and email attributes in the SAML response messages. These attributes are defined through attribute mappings at the identity provider settings.

JIT can be used in combination with most writable user directories, including internal user directories, delegated LDAP, and Atlassian Crowd.
JIT provisioning can very well be combined with SAML group claims. This feature will authorize Atlassian users according to permissions defined at the identity providers. You can read more about this feature here: https://docs.kantega.no/x/D4OLB
Synchronized cloud directories is an alternative solution where a continuous background process keeps a read-only user directory in the Atlassian application updated with users, groups and group memberships. This feature is currently available for Azure, GSuite and Okta.
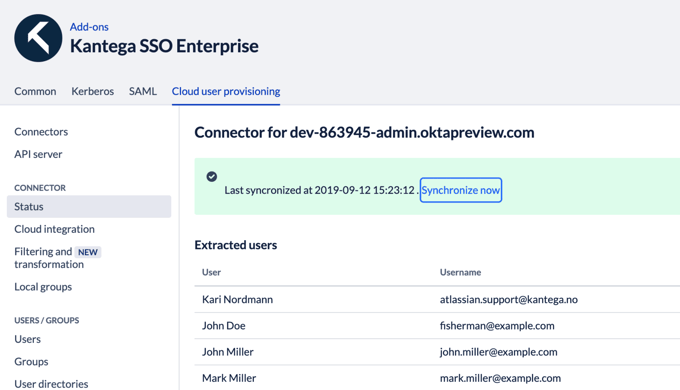
The execution interval for the synchronization job can be configured and by default it is scheduled to run every hour.
You can also configure filters to limit the set users being be exported to Atlassian. The screenshot below shows an example of how Group filters can be defined to only synchronize members of particular groups.
Learn more about how Kantega SSO values customer driven development to ensure product quality and market success.
Redirect to specific SAML identity providers based on email domain, user directory or group memberships.
This article shows how you can combine Jira Service Desk and Confluence to provide solutions, knowledge and optimize the login experience.